写sql的技巧
尽量在sql里进行group
对于汇总类型的报表,往往需要进行分组聚集运算,如果在数据库中先进行一次分组聚集,能够大大减少取到报表服务器的记录数,加快取数和报表运算的速度。
看如下报表:
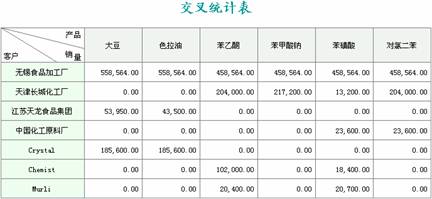
这是一个典型的交叉分组报表,其sql有两种写法:
第一种:select 产品,客户,销量 from 购买记录表
第二种:select产品,客户,sum(销量) from 购买记录表 group by 产品,客户
而报表的做法都一样,如下图所示:

分析:
采用第一种做法,不仅仅取到报表服务器上记录数多了,取数速度慢,而且在报表端对购买记录表进行分组运算的时候速度也慢了;
采用第二种做法,数据库虽然要进行分组运算,但是数据库中有索引,运算速度快,且取到报表服务器端的记录数大大减少,取数速度大大加快,因此在报表端进行分组运算的时候只要对很少的记录数进行,报表的运算速度大大加快了
总结:第二种做法的性能远远优于第一种
尽量不用select * from
对于初学者来说,这是一个很容易犯的错误,例如报表中只需要用到三个字段,但是数据库中实际的表有十个字段,一些初学者习惯性的用select * from table1,这样相当于把十个字段的数据都取到报表服务器端,增加了报表服务器端的内存占用以及减慢了运算速度
正确的写法是:select col1,col2,col3 from table1,即用到哪几个字段就取哪几个,用不着的不要取
尽量在sql里排序
报表中往往需要对数据进行排序,排序运算可以在数据库中进行,也可以在报表端进行,如果报表中的排序规则是确定的,那么建议排序操作选择在数据库端进行,因为数据库中有索引,且数据库是c语言开发的,数据运算速度快。
尽量在sql里过滤
这个问题和2.1、2.2是类似的,报表很多时候并不需要对表中的所有记录进行操作,而是对部分满足条件的记录进行操作,因此建议过滤操作在数据库中进行,这样取到报表服务器端的记录数大大减少,既加快了取数的速度,也加快了报表的运算速度,因为报表需要处理的数据少了。
大数据量可以采用存储过程
有时候,需要用于汇总统计的原始数据量非常大,如果每次生成报表都需要现算,一方面非常慢,另一方面数据库的压力会很大,此时可以采用存储过程对数据预先进行一次压缩,生成中间表,然后再基于中间表生成报表,可以大大提高运算速度并减轻数据库的压力。