分页计算标签
本功能采用报表组的原理来实现,因此需要支持报表组的授权
概念定义
使用分页计算标签可以在报表比较大的情况下实现以页为单位对数据进行读取和展现及导出等操作。
功能背景
报表大到一定程度,必然会内存溢出,此时比较好的解决办法是边算边输出。分页计算标签是利用报表组来实现的逐页计算逐页输出的tag标签。
可以大大降低内存占有量,提高运行效率,避免内存溢出等问题。
extHtml标签使用方法
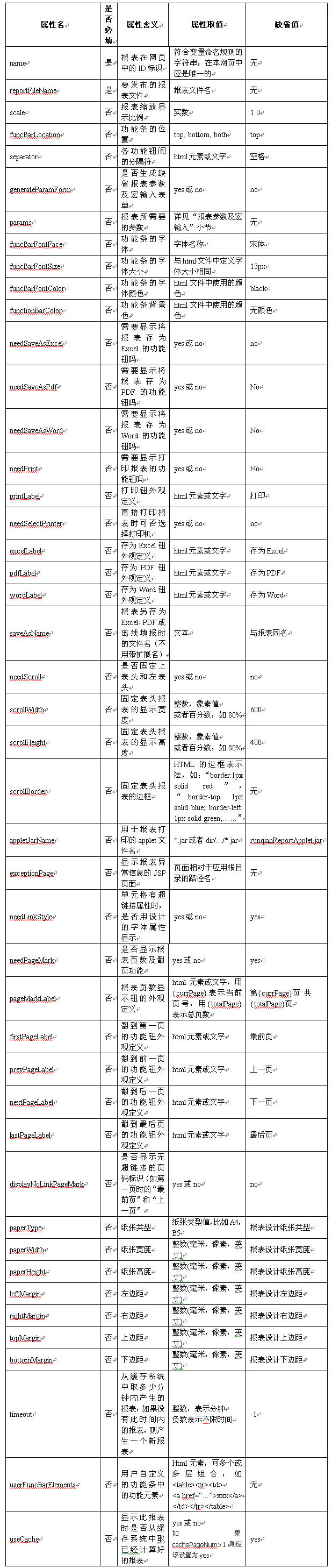
在这个标签中,主要增加了以下属性: totalCountExp——总记录数(必填属性)
分页就是基于这个总记录数来的。它的值是一个润乾的非数据集函数,并且返回的值应该是一个整型数据。如用query执行一个count的sql。如:
totalCountExp="query('SELECT count(*) FROM table1')"
pageCount——每页记录数(非必填) 分页后每一页包含的记录数,其值需为整数。 默认值为20。
cachePageNum——缓存页数(非必填)
根据pageCount和cachePageNum,每次取pageCount* cachePageNum条记录,其值需为整数,默认值为100
设置该属性,可保证缓存页数内的翻页效率。(reportconfig.xml文件里的alwaysReloadDefine设置为no,exthtml标签里useCache设置为yes,该属性才生效) startRowParamName/ endRowParamName——起始行参数名/结束行参数名(非必填)
对应报表数据集记录行中设置的起始行和结束行的参数名。
默认值为startRow和endRow。 其他属性说明,与html标签基本一致:
应用举例一
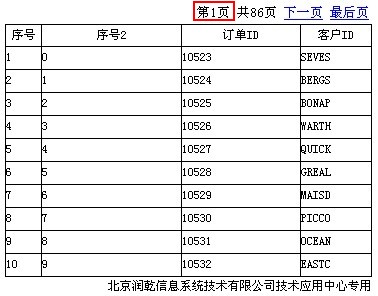
下面以订单明细列表为例,按照常规做出一张订单明细的清单式列表。

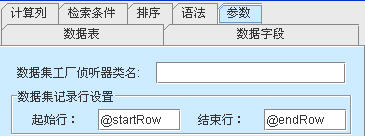
然后为其添加两个参数:起始行参数名startRow和结束行参数名endRow。注意参数类型要求是整型。

并且在数据集设置的参数标签页设置好起始行和结束行的对应参数@startRow和@endRow。
最后,打开缓存开关。将reportconfig.xml文件里的alwaysReloadDefine设置为no,exthtml标签里useCache设置为yes。
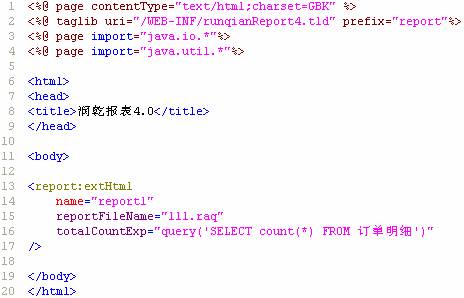
下面是最简jsp发布文件,只定义了三个必须属性,其余均采用默认值:
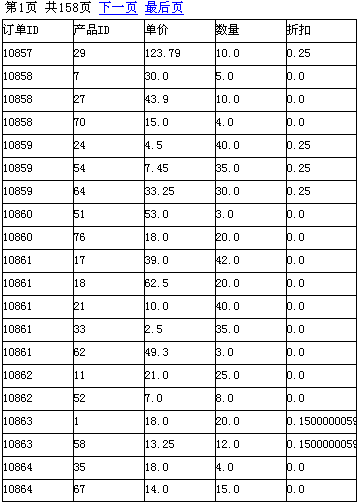
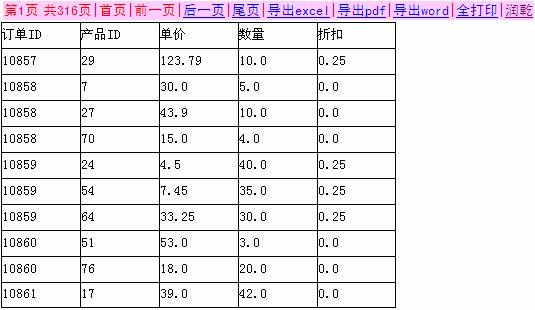
运行结果如下:
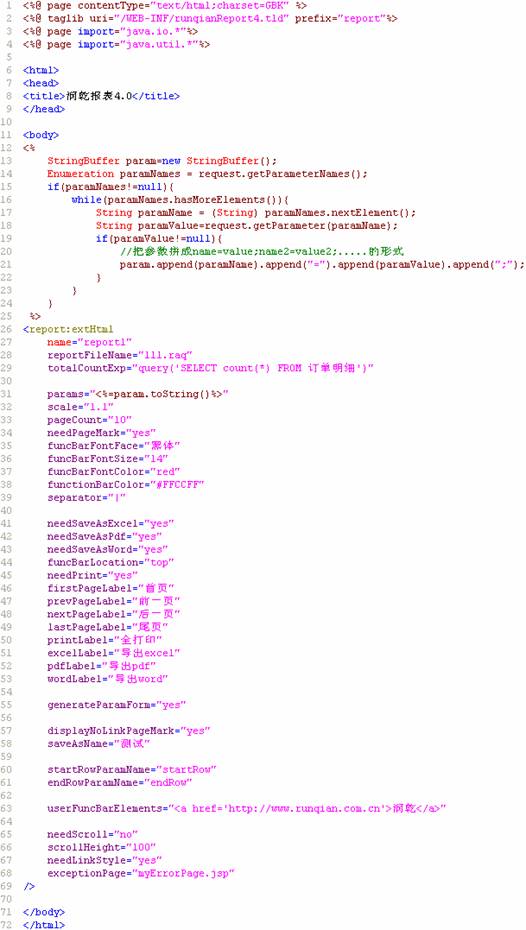
下面是定义了各种属性之后的jsp:
运行效果如下:
这种做法的缺点:当数据量足够大的时候,某些jdbc包的resultset本身会内存溢出;而且从理论上看,当调用api接口将resultset的指针定位到某一行的时候,其底层其实是一行一行跳转的,虽然速度非常快,但是数据量超过几百万甚至几千万的时候,还是会消耗一些时间。因此当记录数大到一定程度,翻到最后一页的速度会比开头几页慢。
这种做法的优点:和数据库类型无关,任何一种数据库都可以采取这种方式,用户不用研究不同数据库的差别。
应用举例二
除了上述方法外。我们还可以利用数据库本身特点,如在oracle数据库中使用rownum。数据集sql如下:
下面以订单明细列表为例,按照常规做出一张订单明细的清单式列表。

添加数据集。创建一【复杂SQL】类型的数据集,在定义标签下输入SQL语句如下
SQL中的两个问号分别对应起始行和结束行参数。(对rownum取大于的时候注意要用别名)。
在【参数】标签下为数据集设置两个整数类型的参数。
最后,打开缓存开关。将reportconfig.xml文件里的alwaysReloadDefine设置为no,exthtml标签里useCache设置为yes。
这种做法的优点:速度非常快,翻页的时候不管翻到哪一页,速度相差很少(1000万条数据每页20行,从第一页直接翻至最后页用时10秒),永远不会内存溢出,理论上可以支持的数据量无限大。
这种做法的缺点:不同数据库做法不一样,oracle提供了rownum关键字,其它数据库不见得提供了,因此用户必须要研究不同数据库的差别,从而找出解决办法。
应用举例三
对于不同的数据库,除了根据本身的特点使用rownum,我们还可以采用存储过程数据集。
根据不同的数据库的采用不同存储过程,在数据集中采用存储过程来分页读取数据。
步骤:
首先,按照常规做出一张清单式列表。
再次,添加数据集。创建一【存数过程】的数据集,在【定义】标签下输入SQL语句如下:
其中的两个问号分别对应起始行和结束行参数。
最后,在【参数】标签下为数据集设置两个整数类型的参数。

最后,打开缓存开关。将reportconfig.xml文件里的alwaysReloadDefine设置为no,exthtml标签里useCache设置为yes。
这种做法的优点:可以充分利用数据库本身的能力,只取出相应行数的记录,速度非常快,翻页的时候不管翻到哪一页,速度相差很少,永远不会内存溢出,理论上可以支持的数据量无限大。
这种做法的缺点:不同数据库做法不一样,存储过程的写法也不同,因此用户必须要研究不同数据库的差别,从而找出解决办法。
总结
上述例子中,第二种和第三种例子的本质是一样的,即充分利用数据库本身的能力,只取出相应页的记录数,避免了resultset的内存溢出以及翻页时的消耗,从而大大提高了性能,理论上数据量可以无穷大。第一种例子的好处在于对数据库没有要求,适合对数据库不太熟悉或者数据库本身没有提供这种能力的用户。
使用方法(autoBig标签)
autoBig标签是对extHtml的优化,可对大报表实现自动分页显示,主要是可以省去原extHtml标签中的totalCountExp、startRowParamName、endRowParamName三个必填参数,并且报表数据集中默认不用指定起始行和结束行参数。
它与extHtml标签相比主要增加了以下三个属性,其他属性与extHtml标签相同:
dbType——数据库类型(必填),只有oracle类型是比较特殊的需明确指定,其他数据库可通用。
dsName——要分页的数据集名称(非必填),如果是报表中的第一个数据集,可不指定。
totalCountExp——总记录数表达式(非必填),分页就是基于这个总记录数计算的。它的值是一个润乾的非数据集函数,并且返回的值应该是一个整型数据。如用query执行一个count的sql。如: totalCountExp="query('SELECT count(*) FROM table1')",默认取dsName属性中设定的数据集sql记录数,区别于exthtml的地方就是可以不再增加startRowParamName 和 endRowParamName参数。
其他属性说明,与html标签基本一致。
注意:
当需要用起始行和结束行控制缓存页记录时则可以在报表中添加_startRow/ _endRow参数实现。
应用举例
一、 数据库类型
1. 步骤
第一步:按照常规做出一张清单式列表。
第二步:打开缓存开关。将reportconfig.xml文件里的alwaysReloadDefine设置为no,autoBig标签里useCache设置为yes。
2. 示例代码1:
最简jsp发布文件,只定义了五个必须属性,其余均采用默认值。
<report:autoBig name="report1"
reportFileName="..."//报表名,必填属性
dbType="SQLSVR"//数据库类型
dsName="ds1"//数据集名称
totalCountExp=""//总条数表达式,为空则默认取dsName属性中设定的数据集sql记录数。/>
3. 示例代码2:
大部分属性与html发布模式的属性相同。
<report:autoBig name="report1"
reportFileName="..."
dbType="SQLSVR"
totalCountExp=""
params="<%=param.toString()%>"
scale="1.1"
pageCount="10"
needPageMark="yes"
funcBarFontFace="黑体"
funcBarFontSize="14"
funcBarFontColor="red"
functionBarColor="#FFCCFF"
separator="|"
needSaveAsExcel="yes"
needSaveAsPdf="yes"
needSaveAsWord="yes"
funcBarLocation="top"
needPrint="yes"
firstPageLabel="首页"
prevPageLabel="前一页"
nextPageLabel="后一页"
lastPageLabel="尾页"
printLabel="全打印"
excelLabel="导出excel"
pdfLabel="导出pdf"
wordLabel="导出word"
generateParamForm="yes"
displayNoLinkPageMark="yes"
saveAsName="测试"
userFuncBarElements="<a href='http://www.runqian.com.cn'>润乾</a>"
needScroll="no"
scrollHeight="100"
needLinkStyle="yes"
exceptionPage="myErrorPage.jsp"
/>
二、采用记录序号
1.步骤
第一步:按照常规做出一张清单式列表。
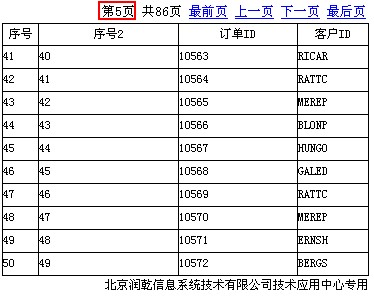
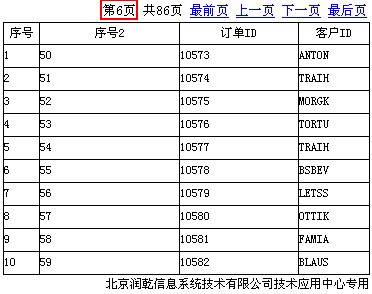
第二步:为其添加两个参数:缓存页的起始行参数名_startRow和结束行参数名_endRow,区分大小写。
第三步:如下“序号2”字段所示,获取每条记录的记录序号。

上述报表在设计器预览内容如下:
2.示例代码1:
<report:autoBig name="report1"
reportFileName="..."
dbType="SQLSVR"
dsName="ds1"
totalCountExp=""
useCache="yes"
pageCount="10"
cachePageNum="5"
/>
上述分页标签中设置的缓存小页数为5,每更换一次缓存大页,A2单元格所显示的扩展单元格的记录序号则会从1开始显示,而B2单元格所显示的记录序号则可通过_startRow记录缓存大页的起始行序号获取,预览结果如下图所示: