写表达式的技巧
or/|| 操作符
使用or操作符时,尽量把值为true的可能性更大的条件表达式放在or的前面,为true可能性更小的条件表达式放在or的后面
原因:or操作符的左右两个操作数,只要有一个为true,其结果必定为true,因此只要第一个条件表达式算出来是true,后面的条件表达式就没必要算了,这样可以加快运算速度。
其次,虽然润乾报表提供了or和||两种写法,这么做仅仅为了方便习惯写or的用户,事实上表达式中写||可以加快表达式的解析速度。
因此建议:尽量写|| ,少写or
and/&& 操作符
使用and操作符时,尽量把值为false的可能性更大的条件表达式放在and的前面,为false可能性更小的条件表达式放在and的后面
原因:and操作符的左右两个操作数,只要有一个为false,其结果必定为false,因此只要第一个条件表达式算出来是false,后面的条件表达式就没必要算了,这样可以加快运算速度。
其次,虽然润乾报表提供了and和&&两种写法,这么做仅仅为了方便习惯写and的用户,事实上表达式中写&&可以加快表达式的解析速度。
因此建议:尽量写&& ,少写and
过滤条件
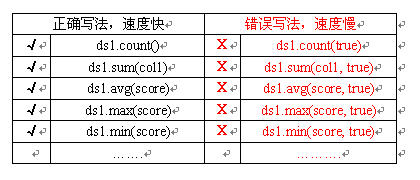
润乾的内置数据集函数中,有不少函数带有过滤条件参数,例如count(), sum(), avg, max(), min() 等等,很多时候可能用户需要把数据集当前记录行集全部选出,而不需要过滤,此时不少用户习惯直接把过滤条件写成true,殊不知,这样导致报表引擎运算时仍旧需要对每条记录进行判断,而如果直接省略该参数,那么引擎就会直接跳过判断,直接进行运算,速度快很多。 .
二分法查找函数bselect1
本文1.3.2中提到了,select1函数是从数据集中检索出满足条件的第一条记录,然后返回该条记录的选出表达式的值,而且还有当前行的概念,可以保证其附属格中以最快的速度从同一条记录中获取相应字段的值。
Select1函数的检索方法是从第一条记录往下遍历,这种检索算法在记录按照检索条件已经排好序的情况下,比二分法慢,因此润乾报表还提供了二分法检索的函数。
bselect1就是采用二分法检索的函数。
二分法检索算法介绍:
例如存在A-Z按照检索条件排好序的23个数据,二分算法首先找到最中间的那个数M,比较M和检索条件是否相等,如果相等,直接返回M,运算结束;如果不等,那么是大了还是小了,假设大了,那么指针直接指向A和M中间的那个数G,再判断是否相等,如果相等,直接返回G,运算结束;如果不等,就看大了还是小了,假设G小了,那么指针直接指向G和M中间的那个数,继续进行判断,以此类推。
数据集函数:bselect1()
函数说明: 此函数功能等同select1(),但是算法不同,采用二分法,适用于数据集记录已经按照参考字段排好序的情况,运算速度比select1()快
语法: datasetName.bselect1(selectExp,"referExp1,referDescExp1,referValueExp1")
参数说明: selectExp 选出字段或表达式
referExp1 参考字段表达式
referDescExp1 参考字段表达式的数据顺序,true表示降序排列,false表示升序排列
referValueExp1 参考字段的值表达式,一旦找到参考字段和该值相同的记录,即返回selectExp的值
......
参考字段及其值可以多个,如果是多个,则找到多个参考字段都和值匹配的记录才返回
rootGroupExp 是否root数据集表达式
返回值: 数据类型不定,由selectExp的运算结果决定
示例:
例1:ds1.bselect1(name,"id,false,value()") 采用二分法,找到数据集ds1中id和当前格的值相等的记录,返回其name字段值
例2:ds1.bselect1(name,"id,false,value();class,false,A1;sex,true,B1")
采用二分法,找到数据集ds1中id和当前格的值相等、class和A1相等且sex和B1相等的记录,返回其name字段值。注意这三个条件在表达式中的顺序必需和它们在数据集中的排序先后相同,也就是说,在数据集中是先对id升序排序,再对class升序排序,最后对sex进行降序排序的。
巧用空值判断nvl
表达式中,经常需要用到空值判断,例如在单元格的显示值属性中,判断当单元格的值为空时,显示为0,否则显示单元格的真实值,等等。一般这种情况下,用户习惯写的表达式是: if(value()==null, 0, value())。
如果我们把value()换成更加复杂的表达式,例如if(ds1.select1(…)==null, 0, ds1.select1(…)),大家可以看出,这种算法明显很慢,需要把ds1.select1(…)这样的复杂表达式运算两次,而如果采用nvl()则可以避免这个问题。
单元格函数:nvl()
函数说明: 根据第一个表达式的值是否为空,若为空则返回指定值
语法: nvl( valueExp1, valueExp2 )
参数说明:
valueExp1 需要计算的表达式,其结果不为空时返回其值
valueExp2 需要计算的表达式,当valueExp1结果为空时返回此值
返回值: valueExp1或valueExp2的结果值
示例:
例1:nvl(A1,"") 表示当A1为空时,返回空串,否则返回A1
例2:nvl(value(),0) 表示当当前格为空时返回0,否则返回当前格的值
应用举例:

数据类型的考虑
数值型的数据,根据其精度不同,可以分成好几种,例如:整型数据有short(16位),int(32位),long(64位),BigInteger(大于64位);浮点型数据有float(32位), double(64位),BigDecimal(大于64位)。
一般来说,精度越高的数据类型,运算速度越慢,因此,如果您的数据长度没有那么长,那么建议选择精度相对比较低的数据类型,可以加快运算速度。
快逸报表提供的数值型转换函数有:
float() 转换成32位的浮点数
double() 转换成64位的浮点数
decimal() 转换成大于64位的浮点数
integer() 转换成32位的整数 long() 转换成64位的整数
bigint() 转换成大于64位的整数
number() 转换成相应的32位整数、64位整数、或者64位符点数
请用户在选择以上函数时根据数据的长度慎重选择。